● Настройка правил - DataGrabber 2.4
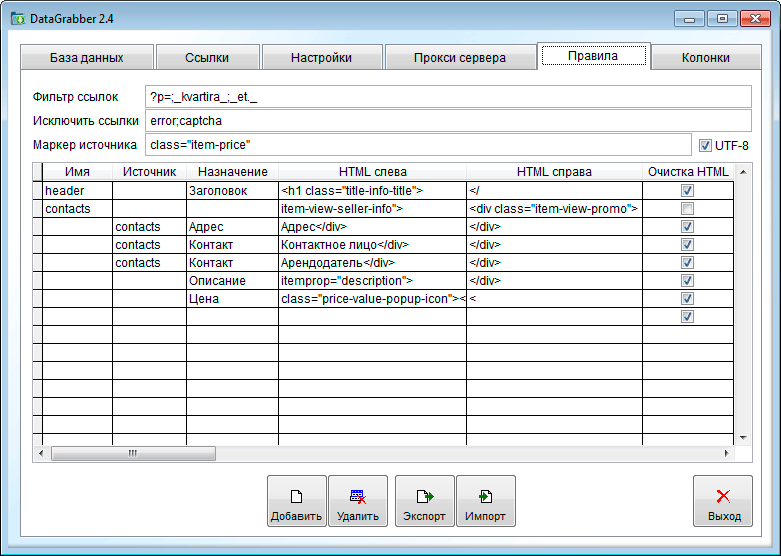
1. фильтр ссылок - здесь через точку с запятой нужно указать текст, который встерчается только в тех ссылках которые нужно обработать, т.е. например для доски объявлений это будут "?p=" - текст который встречается во всех ссылках на страницы со списком объявлений и "_et._" - текст в ссылках на само объявление для недвижимости.
2. Маркер источника - текст который встречается только на страницах объявлений, те страницы с которых предстоит собирать данные
3. UTF-8 - кодировка документа, практически все сайты сделанные правильно идут с этой кодировкой
4. Колонки таблицы настроек - каждая строка это этап обработки HTML документа, суть - вырезать из документа текст обрамленный слева и справа определенным текстом и поместить в указанную колонку результирующей таблицы. (посмотреть HTML код документа, можно либо по правой кнопке мыши "исходный код страницы", либо с помощью средств разработчика). Для того чтобы определить теест слева и справа от нужного контента, смотрите такой текст который больше нигде не встречается в документе, либо ваш идет первым в верстке.
4.1. Имя - имя переменной в которую будет записан результат обработки данной строки (писать на латинице) и который можно будет использовать в последующих обработчиках
4.2. Источник - если пусто, то для обработки будет приниматься весь загруженный HTML код источника, если указан источник (на колонку "имя" которая должна идти перед этой строкой в таблице настроек) то для обработки будет взят ранее "вырезанный" кусок HTML кода. Многошаговая вырезка, делается для того что иногда не получается за один проход вырезать нужный текст из кода страницы.
4.3. Назначение - колонка в таблице результатов, в которую нужно поместить результат обработки
4.4. HTML слева - ограничитель нужного для вырезки текста "слева"
4.5. HTML справа - ограничитель нужного для вырезки текста "справа"
Пример:
<div class="address">Москва, улица Ленина дом 7</div>
для данной строки будет
HTML слева - <div class="address">
HTML справа - </div> или <
Возможно указание несольких правил, для одной результирующей колонки - тогда будет записан последний не пустой результат.
4.6. очистка HTML - очистка резултата от HTML тегов
Пример:
<div class="address">Москва, улица Ленина дом 7</div>
После очистки:
Москва, улица Ленина дом 7
Особенности:
1. Если источник указанный первым правилом встречается несколько раз на странице, а все последующие правила привязаны к нему - будут обработаны все аналогичные варианты на странице.
2. Если первый источник пустой, то все последующие правила не будет обработаны, и строка не будет добавлена в результирующую талицу.
Вас заинтересовало наше предложение? Пишите в Skype: DD-Base , Telegram: @ddbase , Viber: 79374525153 или на емайл: develop@ddbase.ru для обсуждения деталей сотрудничества.








